- Experimental Results
- Deep Dive: ALOHA Robot Rollout Videos & Qualitative Analysis
- Frequently Asked Questions
- BibTeX
(🔊 Turn on sound to follow along with the narration! 🔊)
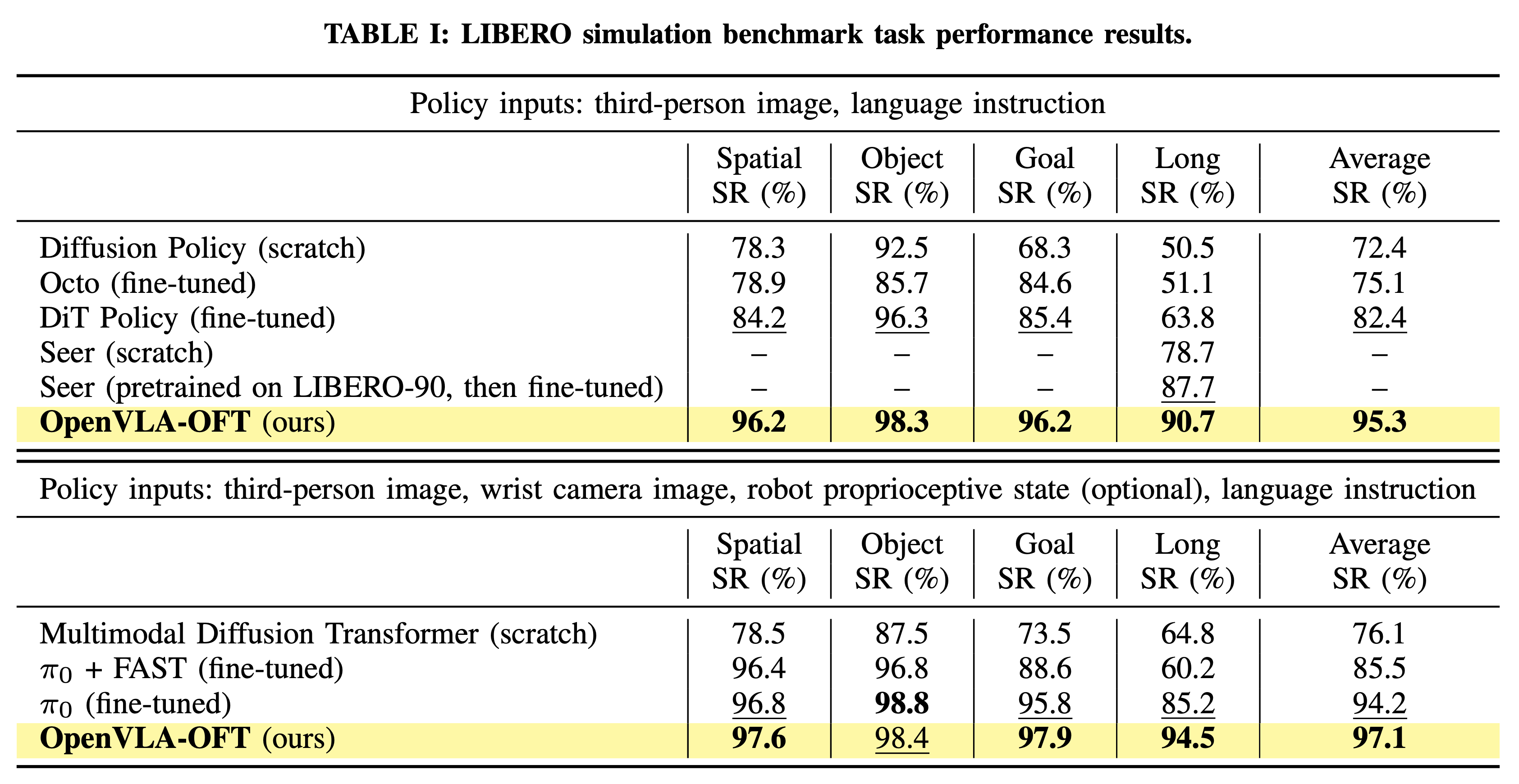
We evaluate OpenVLA-OFT in four LIBERO simulation benchmark task suites, measuring task success rates with and without additional inputs (wrist camera image and proprioceptive state) and comparing it to prior methods. OpenVLA-OFT achieves state-of-the-art results in both categories.

Through parallel decoding and action chunking, OpenVLA-OFT obtains 26x faster action generation speed and 3x lower latency than the base OpenVLA model.
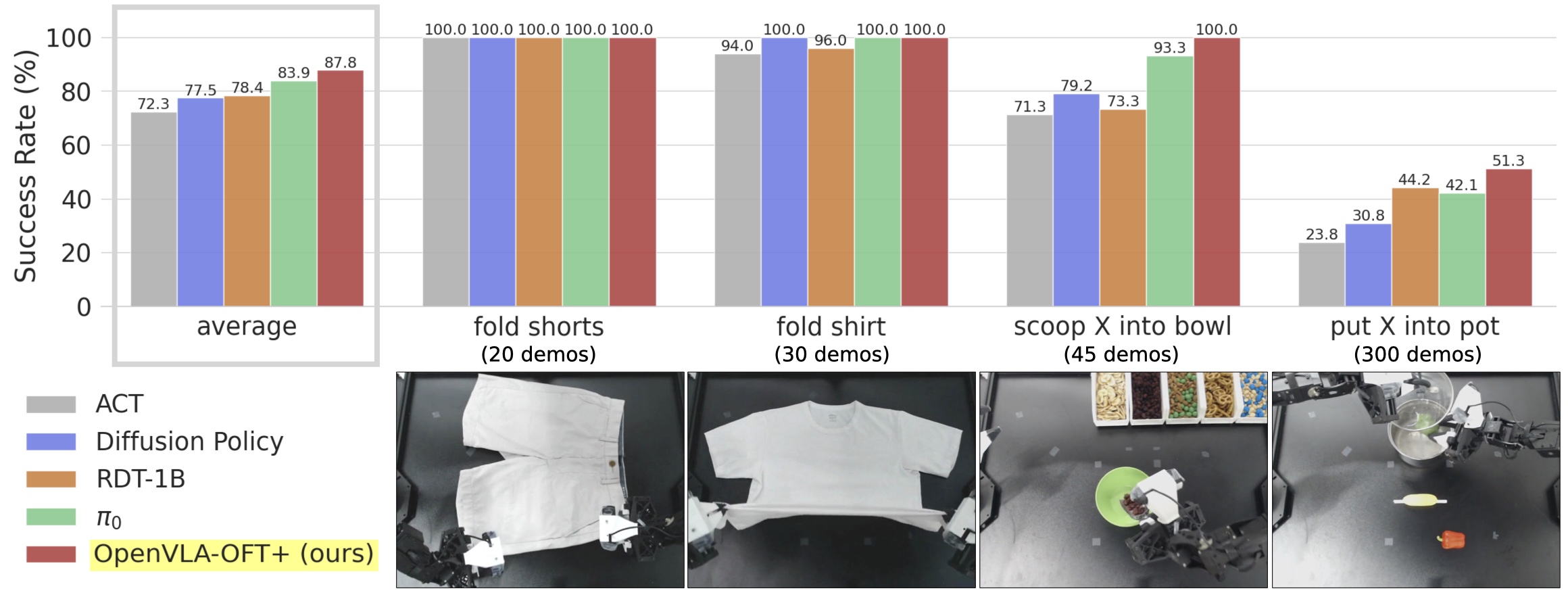
We evaluate both fine-tuned VLAs (RDT-1B, π0, OpenVLA-OFT+) and popular imitation learning policies trained from scratch (ACT, Diffusion Policy) on four representative dexterous manipulation tasks on the ALOHA robot. Fine-tuned VLAs consistently outperform from-scratch policies, with OpenVLA-OFT+ achieving the highest average performance.

We recommend watching the summary video above and reading our paper first before perusing the deep dive below!
Click the arXiv icon below to go to the paper.
In our paper, we evaluate popular imitation learning policies trained from scratch (ACT and Diffusion Policy) and fine-tuned VLAs (RDT-1B, π0, OpenVLA-OFT) on the bimanual ALOHA robot. Here we show real-world rollout videos and focus on qualitative differences between the methods.
All videos below were captured by an external camera and are sped up by 5x unless specified otherwise.
ACT and Diffusion Policy can reliably execute tasks that involve folding clothes and are not dependent on language inputs, as there is just one object to manipulate per task.
In the "scoop X into bowl" task, where the user specifies the target trail mix ingredient via language, ACT and Diffusion Policy approach the correct ingredient most of the time. However, they often make errors during task execution, e.g., hitting the front of the container with the spoon or failing to scoop the ingredients.
Additionally, in the "put X into pot" task, ACT and Diffusion Policy struggle to follow the user's language inputs, often approaching the wrong target object while also making general task execution errors in the process.
The fine-tuned VLAs (RDT-1B, π0, and OpenVLA-OFT+) can also reliably perform the clothes folding tasks, like the previous methods.
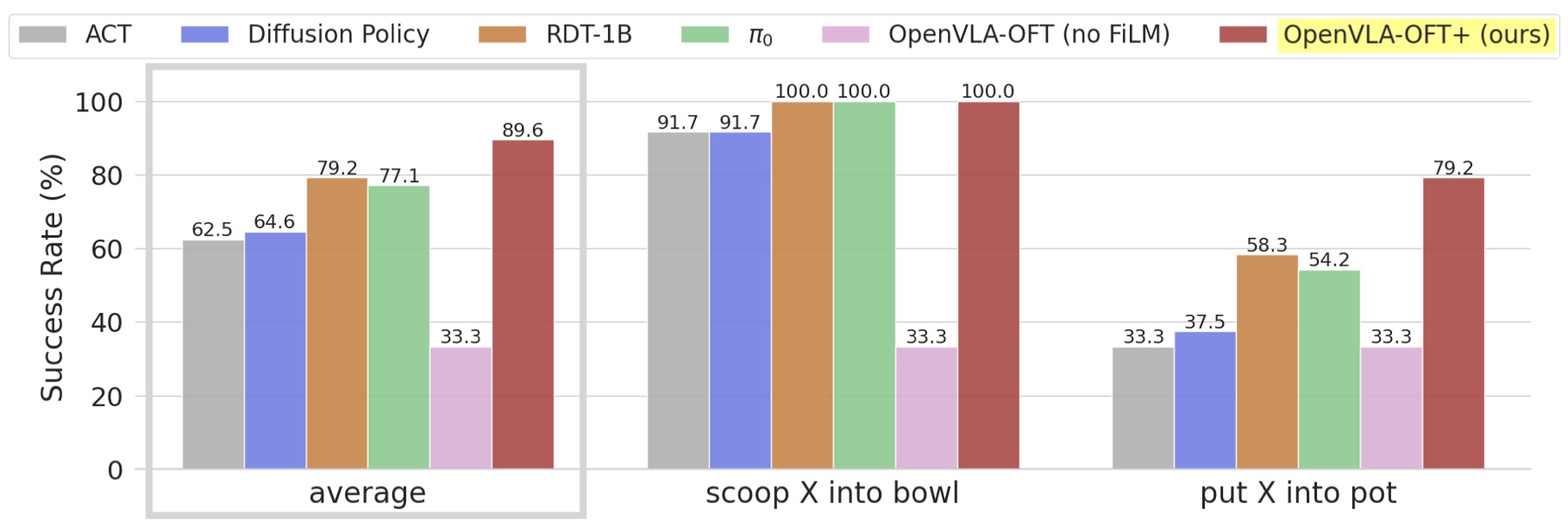
Compared to the non-VLA policies, the fine-tuned VLAs show improved language following and task execution in the "scoop X into bowl" and "put X into pot" tasks.
However, the fine-tuned VLAs are not always successful. In some trials of the "put X into pot" task, π0 approaches the wrong object while RDT-1B approaches the correct one but fails to finish the task. OpenVLA-OFT+, on the other hand, more frequently targets the correct object and completes the task.
One error that fine-tuned RDT-1B makes multiple times in the "scoop X into bowl" task is shown below. Even though the robot misses the bowl at the beginning of the episode, it carries on as if the bowl were correctly placed at the center of the table, proceeding to pour the trail mix ingredients all over the table. We attribute this failure mode to RDT-1B's "Alternating Condition Injection" scheme, which alternates between injecting visual inputs and language inputs in successive transformer layers — a design that encourages the policy to pay more attention to language inputs rather than over-relying on visual inputs. Despite improving the model's ability to follow language, this specially designed architecture may lead to an impaired ability to incorporate visual feedback.
On the other hand, while π0 slightly trails RDT-1B in terms of language following ability, it exhibits better closed-loop visuomotor control. For instance, it occasionally retries after making an initial mistake. OpenVLA-OFT+ demonstrates similar retrying behaviors as well. In the videos below, neither policy finishes the task fully since we reach the time limit (π0 does not drop the pepper into the pot, OpenVLA-OFT+ does not finish closing the pot). However, both methods would have succeeded given more time.
Contrary to the common belief that diffusion-based policies are superior to L1 regression-based policies in imitation learning due to their expressivity and multimodal action modeling capabilities, our findings reveal some important nuances. The characteristics that make diffusion models powerful — e.g., their ability to capture complex action distributions — can lead to issues when training on imperfect demonstration data. Specifically, these models can accurately reproduce even suboptimal behaviors present in the training demonstrations, potentially compromising the policy's performance during deployment. In contrast, L1 policies can benefit from an inherent regularization effect by naturally filtering out noise in training demonstrations through their limited expressivity and committing to the median mode in the task demonstrations. This previously overlooked advantage suggests that simpler algorithms may be more robust than their more sophisticated counterparts in some cases.
We can see this difference clearly in the practical example shown below: When using a diffusion-based fine-tuned VLA (π0) to scoop pretzels, the robot fails because it inserts the spoon too deeply into the container. This problematic behavior arises from reproducing some demonstration sequences where the expert demonstrator had inserted the spoon too deeply into the pretzels container (making it difficult for the policy to retract the spoon afterwards). π0 generates this same behavior two times in twelve trials.
In comparison, our OpenVLA-OFT+ approach, which uses L1 regression, learns to insert the spoon at an ideal depth—neither too deep nor too shallow—and executes the scooping more reliably (achieving 100% success rate on this task).
Note: We do not intend to suggest that L1 policies are universally better than diffusion policies. In fact, if the action distribution in the training set is multimodal, L1 regression-based optimization may lead to learning just one "median" mode in the action distribution (which, importantly, is different from the "mean" mode that MSE regression-based approaches would collapse to). This may not be ideal in certain cases where generating alternative action sequences can be beneficial for task completion. However, in the real world, high-dimensional data such as camera readings are noisy, and with the noise even deterministic policies can produce seemingly "multimodal" behaviors.
Overall, in practice, we find that a simple L1 regression-based approach with a high-capacity policy backbone like OpenVLA proves to be quite effective for adapting to new robots and new tasks.
We show a bonus clip in which OpenVLA-OFT+ autonomously performs the forward task ("scoop X into bowl") and backward/reset task ("pour X into container") in six consecutive rollouts, alternating between the two tasks while cycling through the three trail mix ingredients based on preset language commands. This particular policy was trained on extra data with demonstrations of the backward task. With our strong imitation learning framework, a policy can autonomously execute a task and reset the scene effectively while also exhibiting steerability via language.
(Last updated on 2025-02-22)
How much compute do I need to fine-tune OpenVLA using the OFT recipe? What if I just want to run inference?
Training
For this project, we ran each OpenVLA-OFT training job with 8 A100 or H100 GPUs with 80 GB memory and trained for 50K to 150K gradient steps, depending on the fine-tuning dataset size, which took 1-2 days. We recommend using 4 or 8 GPUs if possible, though you can use fewer GPUs and enable gradient accumulation (which is supported by our fine-tuning script); the training runs will just take longer. Since we fine-tune OpenVLA with LoRA instead of full fine-tuning, there is no need to do model sharding. We simply use Distributed Data Parallel (DDP) and split training samples in a batch across multiple GPUs.
Here is the minimum GPU memory that is needed for each OpenVLA-OFT(+) training configuration with the default bfloat16 data type:
Here is the recommended GPU memory for each OpenVLA-OFT(+) training configuration with the default bfloat16 data type:
Inference
To run OpenVLA-OFT(+) with the default bfloat16 data type, you need less GPU memory:
How does OpenVLA-OFT, which is an L1 policy, outperform fine-tuned diffusion VLAs like RDT-1B and π0, which use more sophisticated algorithms and larger pretraining datasets?
Please see the section on L1 Regression vs. Diffusion.
Does OpenVLA's pretraining help at all if your new fine-tuning recipe uses a different learning algorithm and architecture?
Yes. We ran an ablation study in LIBERO and observed a 5% drop in average success rate when ablating the OpenVLA pretrained representation. See Appendix H and Table XIV in our paper for more details.
Why did you need so many demonstrations for the "put X into pot" task? Even with 300 demonstrations, why is the performance in this task much lower than in other tasks, which seem more difficult?
Number of demonstrations: We do not actually need all 300 demonstrations for satisfactory performance on this task. We simply collected a large number of demonstrations because it was during a point in our project when learned policies were showing poor language following, and we experimented with increasing the training dataset size significantly to test whether this would enable better language grounding. It turned out that simply doubling/quadrupling the dataset size did not solve the problem, as it only slightly improved language following ability. To achieve much better language grounding, we had to take additional measures to encourage the model to pay more attention to language — such as FiLM for fine-tuned OpenVLA policies, which infuses language embedding information into all visual features.
Task performance: This is the first task that we started with and collected demonstrations for on the ALOHA robot setup, and therefore, it is the oldest. We observed significant performance degradation in all methods over time due to hardware-related distribution shifts that arose as time passed (e.g., shifts in the wrist camera viewpoints and slight wear-and-tear in a few robot joints, which affected the dynamics). Earlier on in the project, after we figured out how to imbue policies with enhanced language grounding, we would observe over 90% success rate on this task with fine-tuned OpenVLA policies. However, due to distribution shifts, performance dropped quite significantly when we ran the tests again weeks later. To ensure fair comparisons between methods, we evaluated all methods at the same time so that they all encounter the same train-test distribution shifts — hence the relatively low average rates on this task across all methods.
@article{kim2025fine,
title={Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success},
author={Kim, Moo Jin and Finn, Chelsea and Liang, Percy},
journal={arXiv preprint arXiv:2502.19645},
year={2025}
}